Nakon teorijskog uvoda u Elasticsearch-u (ES)u kojem smo definisali šta je ES, naveli njegove prednosti i opisali proces instalacije i konfiguracije, slijedi dio kada treba praktično primijeniti stečene teorijske osnove. Nadamo se da ste savladali prethodno gradivo i da ste spremni za nove lekcije. :)

Ipak, da biste mogli da radite još bolje, potrebno je da poznajete i sljedeće termine. Riječ je o specifičnoj terminologiji koja se koristi u ES.
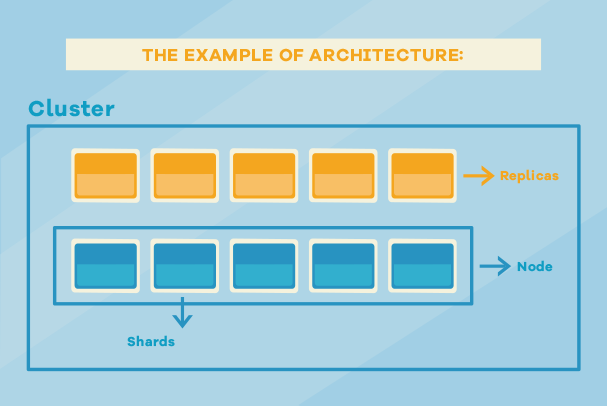
Cluster predstavlja kolekciju čvorova. Broj čvorova nije ograničen. Zajedno, svi čvorovi sadrže sve podatke. Cluster ima jedinstveno ime, a podrazumijevana vrijednost je ‘elasticsearch’.
Čvorovi (eng. node) su, takođe, označeni jedinstvenim imenom i sadrže indekse koji se sastoje od odvojenih fajlova (eng. shards) koji čuvaju indeksirana dokumenta. Kada se radi pretraga nad cluster-om, čvorovi međusobno sarađuju.
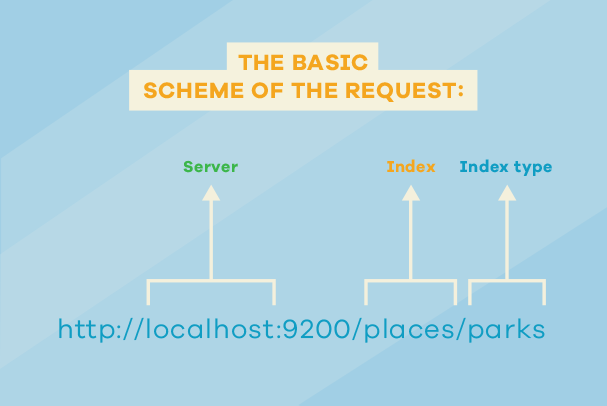
Indeksi (eng. index) predstavljaju kolekciju dokumenata. Svaki dokument ima svoj tip. Imena indeksa su jedinstvena i pišu se malim slovima. Preporuka je da, u skladu sa sadržajem koji želimo da dodajemo na indeks, dajemo i naziv indeksa. Indeksi se koriste za operacije nad dokumentima kao što su: dodavanje, ažuriranje, pretraživanje i brisanje.
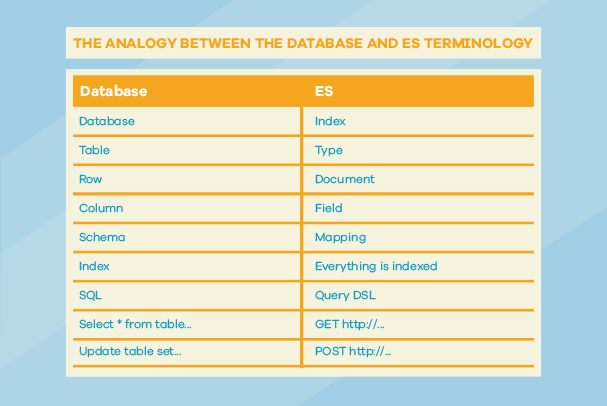
Indekse definišu tipovi dokumenata, a svaki tip indeksa se sastoji od imena i mapiranja. Mapiranje se vrši u trenutku kreiranja indeksa i ne može se naknadno promijeniti. Ono opisuje polja za tip dokumenta. Prilikom dodavanja dokumenta na indeks, ukoliko ne napravimo prethodno mapiranje za tip indeksa, ES će sam odraditi podrazumijevano mapiranje prema dokumentu, tj. podacima koji se indeksiraju. U mapiranju možemo da navedemo naziv i tip polja. Tip polja može biti: string, date, integer, object itd.
Kada kreiramo indeks, definiše se i broj odvojenih fajlova (eng. shards) na koje možemo podijeliti indeks. Podrazumijevana vrijednost za broj odvojenih fajlova je 5. Ovaj broj se definiše prilikom kreiranja indeksa i ne može se naknadno promijeniti. Treba voditi računa o broju, jer veći broj opterećuje procesor.
Na primjer, kada pošaljemo zahtjev za pretragu koja treba da vrati 10 rezultata i ako indeks koji pretražujemo ima 20 odvojenih fajlova za pretragu, pretraga svakog odvojenog fajla se odvija zasebno i svaka pretraga će vratiti 10 najboljih rezultata. U sljedećem koraku se spajaju rezultati posebnih pretraga i od spojenog rezultata se bira 10 najboljih rezultata. Kao što vidite, u ovom primjeru, gdje je indeks imao 20 odvojenih fajlova bez potrebe se odradio posao, čiji je rezultat kasnije odbačen kao nepotreban, a za izvršenje se potrošilo određeno vrijeme.
Lucene, nad kojim je baziran ES, nema tipove za indekse. Tipovi indeksa su implementacija ES i ES u pozadini dodaje filter na dokument i tip indeksa pamti u meta polju “_type” koje opisuje indeks.
Dokument je osnovna jedinica koja se može indeksirati. Dokument je u JSON formatu i sastavljen je od polja koji su predstavljeni parovima key/value, gdje value može biti podatak tipa: string, date, object …
Replika čvora je kopija odvojenih fajlova (eng. shards) indeksa koje taj čvor sadrži. Kopije se prave da bi se postigao veći nivo dostupnosti. Njih nikada ne treba praviti da budu u istom čvoru u kojem se nalaze odvojeni fajlovi od kojih se pravi kopija, jer u slučaju otkaza čvora neće biti dostupni ni čvor, ni kopija. Imati replike znači imati veći broj mogućnosti da se isti dokument, odnosno podatak pročita. To je korisno u slučaju kada u kratkom vremenskom intervalu postoji veliki broj zahtjeva za jednim indeksom na kojem se nalaze traženi dokumenti. Treba voditi računa da veći broj replika usporava proces indeksiranja, tako da, za slučaj kada se upiti dešavaju povremeno, nije preporuka da se pravi veći broj replika.
Čvorovi su mašine – serveri i treba voditi računa da na svima bude postavljena ista verzija ES, a potrebno je obratiti pažnju i na konfiguacione fajlove radi sinhronizacije indeksiranih dokumenata. Bitan parametar je i naziv cluster-a. Ako je u istoj mreži podignuto nekoliko čvorova i parametar cluster.name u konfiguracionom fajlu ima istu vrijednost, to znači i da svi čvorovi pripadaju istom cluster-u. Da smo dodali još jedan čvor u našoj arhitekturi, onda bi u njega ES prenio replike, jer je za replike poželjno da se ne nalaze na istom čvoru kao i orginalni fajlovi. U većini slučajeva, jedan čvor je dovoljan da zadovolji sve potrebe.
Primjeri poziva
Sada ste u potpunosti spremni za praktičnu primjenu naučenog. Za rad ćemo koristiti pretraživač Chrome sa instaliranom ekstenzijom RESTED. Ekstenzija RESTED je jedan od plugin-ova za REST klijent.
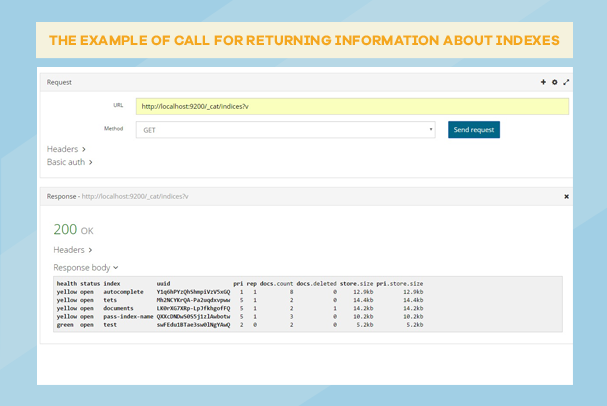
Objašnjenje odgovora:
pri – broj odvojeni fajlova indeksa
rep – broj replika
docs.count – broj dokumenata
docs-deleted – broj obrisanih dokumenata
healt – yellow – ova vrijednost parametra healt znači da postoje replike koje nisu alocirane. Naime, kad kreiramo indeks ES po defaultu, kreira se i jedna replika za indeks, ali pošto imamo jedan čvor, tek kad dodamo druge čvorove u grupu, biće moguće da se odradi alokacija. Kada indeks replike alocira na drugi node, onda će vrijednost parametra healt biti green.
Napomena
Dodavanje indeksa unaprijed, daje nam veću kontrolu i mogućnost konfiguracije i mapiranja indeksa u odnosu na slučaj kad dodamo dokument i ES sam doda indeks sa podrazumijevanim podešavanjima, koja se naknadno ne mogu promijeniti.
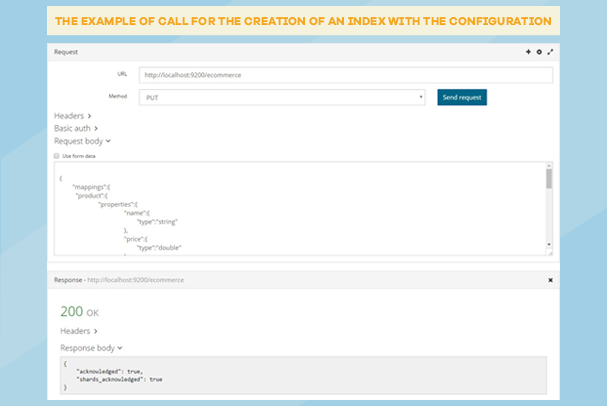
Ostale primjere poziva možete pogledati ovdje.
Odlične performanse u pretraživanju, skalabilnost i denormalizovano čuvanje podataka samo su neki od razloga koji idu u prilog korišćenju Elasticsearch-a. Proces instalacije i konfiguracije je prilično jednostavan, tako da su benefiti korišćenja ES višestruki. Nadamo se da će vam informacije i praktični primjeri biti od pomoći za rad u Elasticsearch-u i da ćete na najbolji način iskoristiti prednosti koje ovaj open source server nudi.